CameraCtrl Timelapse Editor
Python Kivy UI zum Erstellen von Timelapse Videos aus Bildreihen
Inhalt
Die Idee
Nachdem in CameraCtrl und CameraCtrl Schwarm der Fokus auf dem Erstellen und Synchronisieren von Bildern für Zeitrafferaufnahmen lag, geht es mir hier vornehmlich darum, diese Bilddaten zu Timelapse-Videos zusammenzuführen.
Das Erstellen eines Videos aus einer Reihe Bilder habe ich auch bereits abgedeckt. Das Problem das ich hier lösen möchte ist die Auswahl der Bilder. Da ich nun zwei (bzw. beliebig viele) Kameras habe, möchte ich einen übersichtlichen Editor, der mir ermöglicht die Bilder anzusehen, auszuwählen und in die gewünschte Reihenfolge zu bringen.
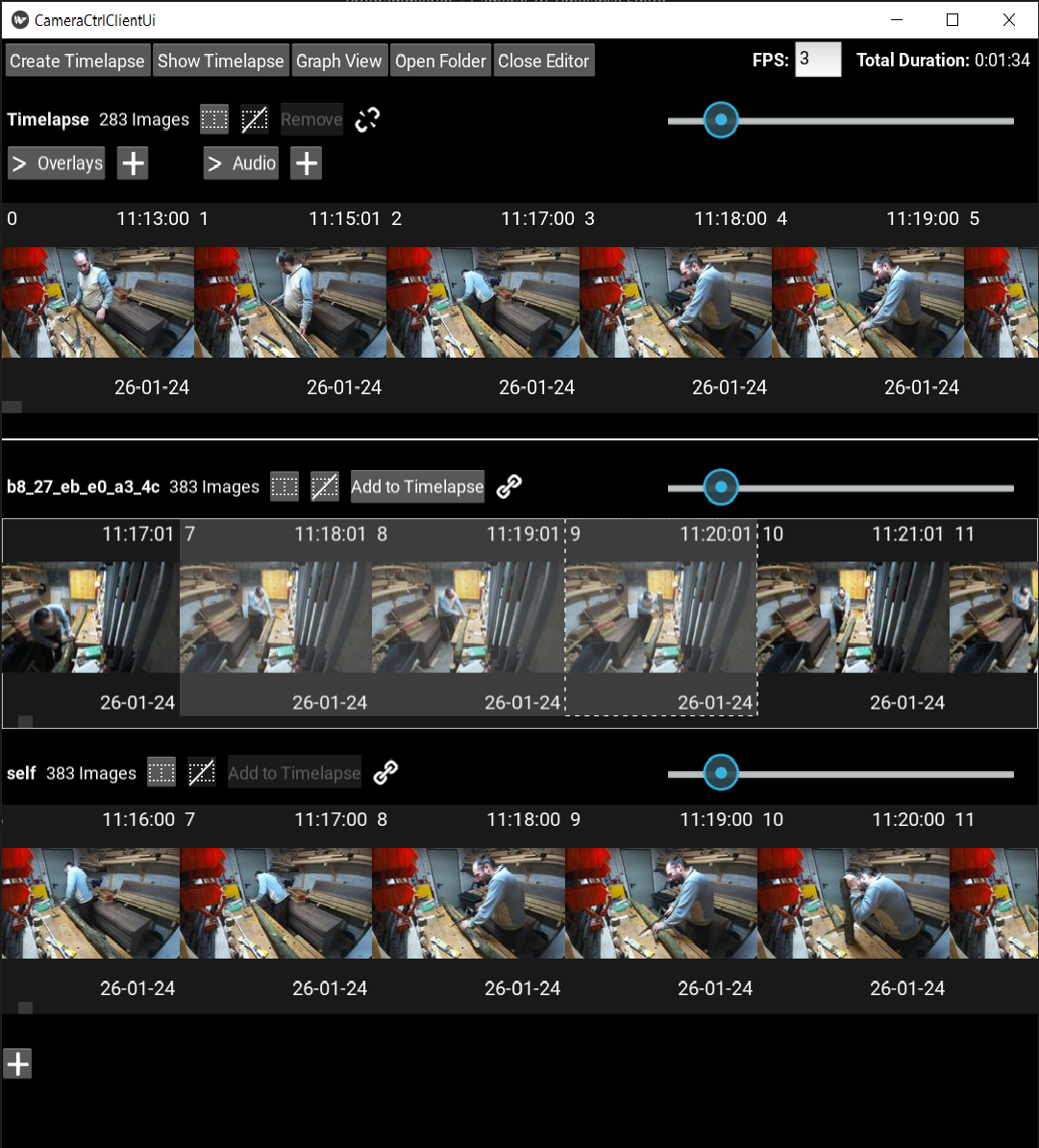
Die grundlegende Idee: Jeder Bildordner wird als scrollbare Leiste von kleinen Bildchen dargestellt. Für die Timelapse-Auswahl gibt es eine eigene Leiste, der ich Bilder aus den anderen Leisten hinzufügen kann.
Den Quellcode findest du hier: CameraCtrl Repository
Screens und ScreenManager
Ich hatte die Client-UI von Beginn an als ScreenManager mit einem einzelnen Screen angelegt.
Daher konnte ich nun direkt einen zweiten Screen für den Timelapse Editor hinzufügen.
Hier der entsprechende Abschnitt in der .kv-Datei:
ScreenManager:
id: screen_manager
MainScreen:
id: main_screen
EditorScreen:
id: editor_screen
Über Button-Klicks wird zwischen den Screens gewechselt. Für diese Screen-Wechsel lassen sich auch ganz einfach nette Übergänge definieren. Ich habe mich für einen einfachen Links-Rechts-Wechsel entschieden (transition.direction = 'left' bzw. 'right').
Entscheidend für mich war, dass ich eine neue unbeschriebene Fläche für den Timelapse Editor habe und zwischen den Ansichten wechseln kann.
Es ließen sich natürlich problemlos weitere Screens anfügen zwischen denen beliebig gewechselt werden könnte. Ich habe den Verdacht, dass ein neuer Screen in vielen Fällen eine bessere und übersichtlichere Lösung darstellt, als z.B. Auswahldialoge in Popups anzuzeigen.
In meiner Implementierung lebte längere Zeit einen Bug, der bei mehrfachem Wechsel der Screens für einen Absturz der UI sorgte. Das lag an meinem Unverständnis darüber, wie so ein Wechsel vonstatten gehen sollte.
Ich hatte mein Glück mit der switch_to-Funktion versucht ohne zu wissen, dass diese den Screen dem ScreenManager hinzufügt sowie den vorigen Screen entfernt. Ich wollte ja weder das eine noch das andere, da beide Screens bereits dem ScreenManager hinzugefügt waren und es auch dabei bleiben sollte.
Lösung: current = 'editor_screen'
So einfach kann es manchmal sein.
Der EditorScreen ist etwa so aufgebaut :
<EditorScreen>:
name: 'editor_screen'
GridLayout:
rows: 2
BoxLayout:
orientation: 'horizontal'
# Hier haufenweise Buttons und Labels...
ScrollView:
id: scroll_view
do_scroll_x: False
# Ein paar Scrollbar-Anpassungen (das kommt später nochmal)...
GridLayout:
id: grid
cols: 1
size_hint_x: None
size_hint_y: None
width: scroll_view.width - dp(10) # Exclude scroll bar
height: self.minimum_height
spacing: dp(4)
Durch das ScrollView ist (wenig überraschend) alles scrollbar. Aber nur vertikal (do_scroll_x: False).
So ist auch bei vielen Bildordnern sichergestellt, dass alles Platz findet.
Ich wundere mich gerade etwas, warum in der ScrollView ein GridLayout steckt. Ich denke, hier wäre ein vertikales BoxLayout naheliegender gewesen. Der Effekt dürfte der Gleiche sein.
In dieses Layout konnte ich nun schön untereinander die Ansichten für die Timelapse-Bildauswahl und die Ordner mit den Bilddaten stecken.
Darin wird horizontales Scrollen möglich sein. Indem die Breite des GridLayout die äußere Scrollbar ausschließt, ist sichergestellt, dass es immer etwas (die Scrollbar) zum Anfassen gibt, um vertikal scrollen zu können.
RecycleView
Nun brauchte ich eine Reihe listenähnlicher Behälter in die ich die vielen Bilder hineinschütten konnte.
Bei der Suche bin ich auf RecycleView gestoßen.
Die Kivy-Dokumentation besagt: “The RecycleView provides a flexible model for viewing selected sections of large data sets. It aims to prevent the performance degradation that can occur when generating large numbers of widgets in order to display many data items.”
Und bezüglich des RecycleViewLayout:
“This module is highly experimental, its API may change in the future and the documentation is not complete at this time.”
Es sah also nach genau dem aus was ich suchte. Und der Hauch von Gefahr ließ es gleich viel aufregender erscheinen. War das Liebe auf den ersten Blick? Spätestens nachdem ich das Ganze rudimentär zusammengeschraubt hatte und es mit hunterten Bildern in Originalgröße (!) klar kam war ich begeistert.
Code
So ist das ImageView aufgebaut (erbt von RecycleView, ich habe leicht gekürzt):
<ImageView>:
viewclass: 'FrameImage' # kommt gleich noch; das ist das Einzelbild
do_scroll_y: False
size_hint_y: None
height: layout.height + dp(10)
scroll_type: ['bars', 'content']
scroll_wheel_distance: dp(114)
bar_width: dp(10)
RecycleBoxLayout:
id: layout
size_hint_x: None
size_hint_y: None
width: self.minimum_width
height: self.minimum_height
orientation: 'horizontal'
spacing: 0
padding: 0
# Item settings:
default_pos_hint: {'center_y': 0.5, 'x': 0}
default_size: root.image_width, root.image_width
default_size_hint: None, None
- Das
ImageViewpasst sich in der Höhe an den Inhalt an. scroll_typeist eigentlich eineScrollView-Eigenschaft. In diesem Fall darf man zum Scrollen sowohl an der Scrollbar als auch am Inhalt anfassen.scroll_wheel_distancefür die Mausrad-Scroll-Geschwindigkeit.- Die Kivy-Scrollbars sind per Default extrem schmal (da auf Mobilgeräten eher getatscht wird). Das lässt sich über
bar_widthändern. - Die Inhalte werden in ein
RecycleBoxLayoutgesteckt. Hier werden auch ein paar Default-Vorgaben für die enthaltenen Elemente gemacht.
Die Elemente erben von RecycleDataViewBehavior und können ansonsten beliebige Widgets sein. Hast du schon erraten was für ein Widget ich verwende?
class FrameImage(RecycleDataViewBehavior, Image)
Du bist sicher ebenso überrascht wie ich.
In der .kv-Datei male ich noch ein bisschen darauf herum:
<FrameImage>:
canvas.after:
# Transparentes Overlay für Selektion
Color:
rgba: .8, .8, .8, root.selection_alpha
Rectangle:
pos: self.x, self.y
size: self.width, self.height
# Gestrichelte Linie, mittels last_selected ganz (1) oder gar nicht (0)
Color:
rgba: 1, 1, 1, root.last_selected
Line:
rectangle: self.x, self.y, self.width, self.height
dash_length: dp(4)
dash_offset: dp(4)
Und benutze AnchorLayouts, um einen laufenden Index für die Bilder, Datum und Uhrzeit anzuzeigen, z.B.:
AnchorLayout:
pos: root.pos
size: root.size
anchor_x: 'left'
anchor_y: 'top'
padding: dp(4), dp(2)
Label:
id: index_label
size_hint: None, None
size: self.texture_size
text: str(root.index)
Das FrameImage ist Wegwerfware wird dabei recycled. Man kann darin keine Zustände erhalten. Die Datenhaltung ist vollständig im ImageView geregelt. Dort halte ich alle Infos in self.data: list[dict] mit je einem dict pro FrameImage.
Aktualisiert wird das FrameImage über die Funktion refresh_view_attrs(self, rv, index, data). Dort kann man sich alles was man braucht aus data rausholen.
Wenn sich etwas an der Datenhaltung ändert, kann man über die RecycleView-Funktion self.refresh_from_data() für eine Aktualisierung der Ansicht sorgen. Wenn man gnädig ist, gibt man noch die geänderten Indizes an, um dem armen Ding etwas Arbeit zu ersparen:
self.refresh_from_data(modified=slice(refresh_slice_start_idx, frame_count, None))
Aber auch so habe ich nie gemerkt, dass dabei irgendetwas hängt.

Optimierung
Nach all dem Lob muss ich nun doch noch eine Einschränkung machen. Mir war schon klar, dass es keine gute Idee ist, die Bilder in Originalgröße zu laden und dann erst für die Anzeige runterzuskalieren. Ich war überrascht wie gut das ging, doch beim ersten Scrollen durch eine RecycleView führte das Laden der Bilder dazu, dass die Sache etwas ruckelig vonstatten ging. War man einmal durch konnte man anschließend aber sanft hin und her scrollen.
Lösen ließ sich das Problem durch das Generieren von Thumbnails (bei denen das Laden dann auch nicht weh tut).
Das war für’s erste ganz nett, aber wenn man sich die durchweg sanfte Benutzung damit erkauft, dass man vorher eine Weile auf die Thumbnail-Generierung wartet, auch noch nicht so richtig überzeugend. Die Generierung musste natürlich im Hintergrund passieren.
Dafür benutze ich wieder mal den APScheduler genauer AsyncIOScheduler:
scheduler.add_job(self._copy_thumbs, 'date', run_date=datetime.now())
So entkomme ich dem Main-Thread. Ich muss nur aufpassen, dass ich von außerhalb nicht die UI manipuliere, sonst wird Kivy sauer. Aber es lässt sich mit dem @mainthread-Decorator besänftigen. Derart dekorierte Funktionen führen den Aufruf wieder im Main-Thread zusammen und können unbesorgt die UI manipulieren.
Bei der Thumbnail-Generierung habe ich der UI immer gebündelt für 5 Bilder Bescheid gegeben (über refresh_from_data()) und im Falle, dass das Thumbnail schon existierte sogar kurz geschlafen (sleep(0.001)). So konnte ich ein schön sanftes Erlebnis produzieren. Meistens merkt man gar nicht, dass da noch etwas lädt, außer man scrollt ganz schnell nach rechts (dann sieht man erstmal nur weiße Platzhalter anstelle der Bilder). Damit das nicht falsch aufgefasst wird, sorge ich über Events dafür, dass in der Bedienzeile der Hinweis Loading... angezeigt wird, solange eben dies der Fall ist.
Moment. Bedienzeile? Die hatte ich bisher verschwiegen. Aber jetzt ist es raus: Zu jeder ImageView habe ich noch ein weiteres Widget namens ImageViewControls, um das Ganze bedienen zu können.
ImageViewControls
Die Bedienleiste ist recht eng mit der zugehörigen ImageView verknüft. Ich habe ihr die ImageView im Konstruktor übergeben, damit sie direkt darauf arbeiten kann.
Anderes läuft über Events. Was Kivy nicht sowieso von Haus aus mitbringt habe ich neu definiert.
Im Beispiel des Loading... habe ich ein neues Event in der ImageView registriert:
self.register_event_type('on_loading_state_change')
Sie muss diese Funktion auch definieren:
def on_loading_state_change(self, loading: bool):
pass # Hier könnte die ImageView selbst auf das Event reagieren
Und kann das Event dann nach Belieben senden: self.dispatch('on_loading_state_change', True)
Die ImageViewControls hören darauf:
# Im Konstruktor
image_view.bind(on_loading_state_change=self._on_loading_state_change)
# Und hier die Listener-Funktion
def _on_loading_state_change(self, _instance, loading: bool):
self.ids.loading_label.opacity = 1 if loading else 0
Die Bedienelemente für einen Quellordner sind (zum Teil) andere als die Bedienelemente für die Timelapse. Andererseits teilen sich beide ganz viel Funktionalität.
Das habe ich darüber abgebildet, dass beide von einer gemeinsamen Basisklasse AbstractImageViewControls erben. In der .kv-Datei sieht es mit der Vererbung schlecht aus, daher habe ich mich entschieden, für die abstrakten Klasse keine UI-Elemente anzulegen. ImageViewControls und TimelapseViewControls definieren jeweils ihr eigenes Layout und ihre Kind-Widgets.
Alternativ könnte man um noch weniger Code zu duplizieren auf die UI-Beschreibung in der Kivy-Datei verzichten und den gesamten Widget-Baum im Python-Code aufbauen. Aber das wäre dann deutlich umständlicher und unübersichtlicher.
Eine bessere Alternative könnte sein, der abstrakten Klasse doch ein Layout mit allen geteilten Elementen zu verpassen und für die abweichenden Elemente leere Layouts zu hinterlegen, die dann in den abgeleiteten Klassen gefüllt werden könnten. Dabei könnten auch Gruppen von UI-Elementen gemeinsam in der UI-Beschreibung definiert und dann als Ganzes eingefügt werden.
An anderer Stelle arbeite ich damit, dass ich alles in ein Layout stecke und dann unter bestimmten Bedingungen etwas umgestalte (z.B. Anzeigetext ändern), verstecke oder wieder aus dem Layout herauslösche. Was dann z.B. bei einem Button-Klick passiert lässt sich durch Überschreiben der Funktion in der abgeleiteten Klasse oder durch Übergeben der Zielfunktion an die übergeorndete Klasse steuern.
Jede ImageView hat ihre eigene Scrollbar. Dadurch ist das Scrollen in der jeweiligen Ansicht natürlich unabhängig von den anderen Ansichten. Ein häufiger Anwendungsfall ist jedoch, dass ich Bilder aus verschiedenen Ansichten miteinander vergleichen möchte, um mich jeweils zwischen ihnen entscheiden zu können. Daher habe ich einen Button eingebaut mit dem das Scrollen einer Ansicht mit dem der anderen Ansichten verknüpft werden kann.
Das habe ich so umgesetzt, dass ich in den ImageViewControls auf das Scrollen der eigenen View höre und falls der Button aktiv ist allen anderen ImageViewControls Bescheid gebe:
# Hören (in der __init__-Funktion):
image_view.bind(scroll_x=self.this_scroll_x)
# Sagen:
def this_scroll_x(self, instance, scroll_x):
if self.ids.link_btn.state != 'down':
return
self.scroll_callback(instance, scroll_x)
# Und schauen was die anderen so machen:
def other_scroll_x(self, instance, scroll_x):
if self.ids.link_btn.state != 'down':
return
if instance == self.image_view:
return
self.image_view.scroll_x = scroll_x
Das scroll_callback ist dabei eine Funktion des EditorScreen. Dieser ruft dann das other_scroll_x aller ImageViewControls auf.
Über einen Slider kann die Vorschaugröße verändert werden. Dabei wird über das entsprechende Event von den ImageViewControls die Größe in der ImageView gesetzt.
Da es sich um ein Kivy-Property handelt (image_width = NumericProperty(dp(160))), bringt es selbst wieder ein Event mit das automatisch bei Änderung gefeuert wird.
Und da ich im .kv für das RecycleBoxLayout die Default-Größe als default_size: root.image_width, root.image_width (Breite gleich Höhe) definiert habe, wird automatisch auf dieses Event gehört. Da ich im FrameImage die Größe nicht überschrieben habe werden so auf magische Weise alle Vorschaubilder passend skaliert.
Da wir jetzt so gut wie alles beisammen haben, kann ich ja schon mal das Gesamtbild enthüllen:
Overlays und Audio
Bisher wurde bei der Timelapse-Generierung nur eine Audio-Datei berücksichtigt, die dann über das gesamte Video hinweg geloopt wurde. Das habe ich so umgeschrieben, dass nun eine beliebige Anzahl Audio-Dateien übereinandergelegt werden können (z.B. Hintergrundmusik und Kommentar) und auch der Abschnitt definiert werden kann in dem die jeweilige Audio-Datei abgespielt wird.
So konnte ich nun Overlays und Audio für die Darstellung im Editor fast gleich behandeln.

Beides lässt sich über den jeweiligen Button ausklappen (auch beides gleichzeitig).
Dabei wird für den jeweiligen Bereich die Sichtbarkeit geändert (opacity = 0 bzw. 1) und damit es keinen (“leeren”) Platz mehr einnimmt alle Widgets rausgeschmissen und beim Einblenden neu erzeugt.
Es wäre naheliegend gewesen, hier wieder eine RecycleView für jede Audio- bzw. Overlay-Datei zu verwenden, die synchron mit der TimelapseView scrollt, aber ich wollte etwas Neues ausprobieren. Der Bereich für Audio und für Overlays ist jeweils eine ScrollView, die mit dem Scrollen der TimelapseView synchronisiert wird. Darin steckt ein vertikales BoxLayout.
Für jede Audio- bzw. Overlay-Datei gibt es dann einfach ein sehr breites einzelnes Widget (ich nenne es FileListEntry) für das ich zwei Texturen erstelle (eine für den ausgewählten Bereich und eine für den nicht ausgewählten). Die Textur besteht quasi aus dem Bild und der Information, wie oft es wiederholt wird und kann dann im canvas des Widget gemalt werden:
canvas.before:
Rectangle:
pos: self.pos
size: self.size
texture: root.disabled_texture
Rectangle:
pos: self.texture_pos_x, self.y
size: self.texture_width, self.height
texture: root.texture
Für Größen und Position wird dann ein bisschen rumgerechnet (die Gesamtgröße entspricht z.B. der Breite eines Bildes in der Timelapse-View mal der Anzahl der Bilder in der Timelapse-View).
Die Textur (hier für den ausgewählten Bereicht) wird folgendermaßen erstellt:
self.texture_pos_x = start_frame * image_width
self.texture_width = (end_frame + 1) * image_width - self.texture_pos_x
# noinspection PyArgumentList
self.texture = Texture.create(size=(image_width, image_width), colorfmt='bgra')
self.texture.wrap = 'repeat'
repeat_count = self.texture_width / self.image_width
self.texture.uvsize = (repeat_count, 1)
image_bytes = get_image_buffer_fit_to_frame(image_path, image_width, image_width,
draw_border=True)
self.texture.blit_buffer(image_bytes, colorfmt='bgra', bufferfmt='ubyte')
Die Funktion get_image_buffer_fit_to_frame malt noch ein bisschen im Bild herum (hier wird der Rahmen ins Bild gemalt, damit es ausgewählt aussieht) und wandelt es in Bytes um, damit der Textur-Buffer es schluckt.
def get_image_buffer_fit_to_frame(
image_path: Path, width: int, height: int,
draw_border: bool = False,
border_color: tuple[int, int, int, int] = (255, 255, 255, 255),
cover: bool = False,
cover_color: tuple[int, int, int, int] = (0, 0, 0, 0),
cover_weight: Annotated[float, ValueRange(0.0, 1.0)] = 0.5
) -> bytes:
image = cv2.imread(str(image_path), cv2.IMREAD_UNCHANGED)
image = fit_image_to_frame(image, width, height)
if draw_border:
thickness = 2
cv2.rectangle(image, (0, 0), (image.shape[0] - 1, image.shape[1] - 1),
border_color, thickness)
if cover:
rect = np.full(image.shape, cover_color, dtype=np.uint8)
image_weight = 1.0 - cover_weight
image = cv2.addWeighted(image, image_weight, rect, cover_weight, 1.0)
buffer = cv2.flip(image, 0)
return buffer.tobytes()
Das cover ist für die Textur des nicht ausgewählten Bereichs gedacht und legt eine teil-transparente Fläche über das Bild, um es etwas abzudämpfen.
Die Funktion fit_image_to_frame habe ich bei der Timelapse-Generierung bereits verwendet. Sie skaliert das Bild. Wenn das Format nicht passt werden (i.d.R. unten und oben) schwarze Balken eingefügt.
Das war es dabei auch schon fast. Noch ein paar Dialoge zum Hinzufügen und Editieren und dann ein Kontext-Menü über das sich alles bedienen lässt. Insbesondere kann dabei die Start- und End-Position festgelegt oder der gesamte Bereich an die entsprechende Stelle verschoben werden.
Beim Kontextmenü ist die Positionierung vielleicht noch ganz interessant und dass es mir zum ersten Mal gelungen ist, die Größe des Popup sauber auszurechnen.
Hier der Ausschnitt der Kivy-Datei:
<FileListEntryContextMenu>:
size_hint: None, None
width: max(layout.width, self.title_width) + dp(40)
height: layout.height + root.title_size + dp(60)
pos_hint: {'x': self.rel_x, 'top': self.rel_top}
BoxLayout:
id: layout
# Jede Menge Buttons...
Die Positionierung des Popup muss über relative Werte erfolgen (auch wenn es eine Weile brauchte bis ich das akzeptieren konnte).
Sie wird im FileListEntry aufgrund der Touch-Position berechnet. Kivy geht immer erstmal von Touch aus, aber das klappt auch mit der Maus. Ich kann auch über touch.button == 'right' feststellen, dass die rechte Maustaste betätigt wurde.
# Erstmal die Position vom Widget zum Window umrechnen
touch_x, touch_y = self.to_window(*touch.pos)
# Und der Rest ist relativ
rel_x = touch_x / Window.width
rel_y = touch_y / Window.height
Hier nun der Python-Code-Ausschnitt zum Kontextmenü:
class FileListEntryContextMenu(Popup):
title_width = NumericProperty(0)
rel_x = NumericProperty(0)
rel_top = NumericProperty(0)
def __init__(self, rel_x: float, rel_top: float,
# Jede Menge Button-Callbacks...
**kwargs):
self.rel_x = rel_x
self.rel_top = rel_top
super().__init__(**kwargs)
size_calc_label = CoreLabel(font_size=self.title_size)
self.title_width = size_calc_label.get_extents(self.title)[0]
Clock.schedule_once(self._after_init)
def _after_init(self, _dt):
if self.x + self.width > Window.size[0]:
self.rel_x = (Window.size[0] - self.width) / Window.size[0]
if self.y < 0:
self.rel_top = self.height / Window.size[1]
Die relevanten Werte sind Kivy-Properties damit Änderungen auch direkt in der UI ankommen.
Der Trick für die Größenberechnung liegt darin, dass ich den Text in ein CoreLabel stecke mit dem ich die Größe berechnen kann ohne es anzeigen zu müssen.
Nachdem das Menü positioniert ist (einmal Kivy Clock durchnudeln), wird nun in der _after_init noch nachjustiert, falls es nicht ins Bild passen sollte. Ich muss nur rechts und unten prüfen, da das Menü rechts unterhalb der Klick-Position angezeigt wird.
Man kann hier auch schön sehen, dass bei Kivy die Y-Achse von unten nach oben verläuft.
Graph View
Die Graph-Ansicht habe ich eingebaut, um einen guten Überblick über das Projekt zu ermöglichen. Dafür verwende ich Matplotlib (zum ersten Mal). Ich habe eine ganze Weile damit herumgefuhrwerkt bis ich halbwegs verstanden habe was ich tue und alles so hatte wie ich es wollte. Matplotlib fordert sicher einige Einarbeitung, ist aber auch extrem mächtig.
Bei der Darstellung interessiere ich mich nur für die Zeitdaten der Bilder. Ich habe also je ImageView eine Liste mit datetime-Objekten.
Die Zeitreihen zu den ImageViews sind auf der Y-Achse angeorndet (also untereinander). Dabei ist wieder zu bedenken, dass ich von oben nach unten lesen möchte (die TimelapseView soll als erstes kommen usw.), aber die Achse natürlich von unten nach oben verläuft.
Auf der X-Achse liegt dann der Zeitstrahl.
So kann ich gut Unterschiede zwischen den einzelnen ImageViews erkennen und wo ich im fertigen Video Lücken habe (nicht dass es immer schlecht wäre, etwas rauszuschneiden).
Über die Anordnung auf einem Zeitstrahl kann ich allerdings keine Sprünge in der Kontinuität darstellen, also dass die zeitliche Reihenfolge durcheinander ist, weil die Daten per Definition sortiert dargestellt werden. Darum habe ich die betroffenen Punkte rot eingefärbt. So kann ich zwar nicht erkennen, wo das Bild mit dem entsprechenden Datum jetzt gelandet ist, aber immerhin dass es an der falschen Stelle ist (auch das kann natürlich Absicht gewesen sein). Und wenn ein Datum mehrfach auftaucht, kann ich das anhand der Markierungen auch nicht erkennen, daher habe ich in solchen Fällen die Anzahl daruntergeschrieben.
So sieht die Plot-Funktion aus (np steht für numpy):
def plot_timelines(timelines: list[list[datetime]],
timeline_labels: list[str], title: str = ""):
fig, ax = plt.subplots(nrows=1, figsize=(12, len(timelines)),
layout="constrained")
fig.canvas.manager.set_window_title(title)
ax.set(title=title)
ax.margins(y=1)
# Format x-axis labels
ax.xaxis.set_major_formatter(mp_dates.DateFormatter('%d-%m-%Y\n%H:%M:%S'))
ax.tick_params(axis='x', labelrotation=275, bottom=False)
# Set y-axis labels
ticks = np.arange(1, len(timeline_labels) + 1)
ax.set_yticks(ticks, labels=reversed(timeline_labels))
ax.tick_params(axis='y', left=False)
# Process the timelines
y_coord = len(timelines)
for timeline in timelines:
# Fill in the dates
in_order = [timeline[0]]
out_of_order = []
for date in timeline[1:]:
if date < in_order[-1]:
out_of_order.append(date)
else:
in_order.append(date)
ax.plot(in_order, np.full(len(in_order), y_coord),
linewidth=0.5, marker="|", color="#2B83FF")
ax.plot(out_of_order, np.full(len(out_of_order), y_coord),
linewidth=0., marker="|", color="red")
# Add count labels for duplicates
duplicates = [(date, count)
for date, count in Counter(timeline).items() if count > 1]
for date, count in duplicates:
x = mp_dates.date2num(date)
ax.annotate(str(count), (x, y_coord), xycoords='data',
textcoords='offset points', xytext=(-2, -9),
fontsize=8,
arrowprops=dict(width=0, headwidth=0, headlength=0))
# Next timeline y coord
y_coord = y_coord - 1
plt.xlabel('Dates out of chronological order are marked red.\n'
'For multiples the number of occurrences is shown.')
# Remove spines
ax.spines[["left", "top", "right", "bottom"]].set_visible(False)
# Show vertical grid lines
ax.grid(axis='x', visible=True, which='both', color='lightgray')
Und das ist der resultierende Graph:

Insbesondere bei größeren Projekten mit vielen Bildern finde ich es sehr nützlich, dass ich das Fenster vergrößern und beliebig in der Ansicht zoomen kann ohne Qualitätsverluste.
Weiteres
Es sind noch eine ganze Reihe weiterer Details im Timelapse Editor verborgen wie z.B. rudimentäre Tastaturnavigation oder eine große Vorschau einschließlich Vor- und Zurück-Button sowie der Möglichkeit automatisch in einer vorgegebenen Geschwindigkeit (FPS) die Bilder zu wechseln (quasi wie im fertigen Video). Aber ich denke, dass es da zum Code nicht viel zu erzählen gibt, daher lasse ich es.
Projektdateien
Interessant ist vielleicht noch die Projektstruktur, also wie die Verzeichnisse aufgebaut sind und wie die Daten abgelegt werden.
Beim Öffnen des Timelapse Editors wähle ich ein Verzeichnis aus (das zuletzt geöffnete ist vorausgewählt). Es wird erwartet, dass darin Unterverzeichnisse mit Bildern liegen.
Ich kann aber auch mit einem leeren Verzeichnis starten und dann alles über die jeweiligen +-Buttons für Bildordner, Audio oder Overlays importieren.
Die Ordner _audio, _overlays und _editor_data haben eine spezielle Bedeutung.
_audio und _overlays lassen sich noch gut manuell füllen und sobald ich den entsprechenden Bereich aufklappe, werden die jeweiligen Dateien gefunden. Start- und End-Position sind dabei im Dateinamen hinterlegt, aber fehlende oder unsinnige Angaben sind auch kein Problem.
Der Ordner _editor_data sollte hingegen in Ruhe gelassen werden, wenn man nicht genau weiß, was man da tut.
Darin liegt direkt die Projekt-Konfiguration im project.json (nicht verwechseln mit den verschiedenen JSON-Konfigurationsdateien im Anwendungsverzeichnis). Sie enthält aktuell nur ein paar wenige Einträge, nämlich Auflösung, FPS und Dateipfad für das Video.
Und dann gibt es noch je ImageView einen Unterordner mit den jeweiligen Thumbnails und dem etwas unpassend benannten timelapse.json mit zusätzlichen Infos zu den Bildern (ursprünglich war das nur für die Timelapse gedacht, aber es hat sich für die anderen Bildordner auch als nützlich herausgestellt). Diese Thumbnail-Ordner zu den Bild-Quellordnern werden aber beim Anwendungsstart geprüft, aufgeräumt oder auch neu erstellt.
Der Ordner für die Thumbnails der Timelapse heißt _timelapse_images. Das ist also ein weiterer Ordnername, der im Projektverzeichnis gemieden werden sollte. Er ist fast genauso aufgebaut, nur dass zusätzlich noch das Quell-Bild nachvollzogen werden kann. Die Reihenfolge der Bilder wird über das timelapse.json vorgegeben in dem Bilder natürlich auch mehrfach auftauchen können.
Änderungen in diesem Ordner haben eine direkte Auswirkung auf das Projekt.
Test Coverage
Bei der Entwicklung von CameraCtrl habe ich das Schreiben von automatisierten Tests etwas vernachlässigt und bei der Erweiterung um den Timelapse Editor zunächst gänzlich ignoriert.
Mir ist jedoch bewusst, dass das keine gute Idee ist. Ich hatte bei der schrittweisen Erweiterung erstaunlicherweise kaum das Problem, dass meine Änderungen etwas kaputt gemacht haben. Ich nehme an, das liegt vornehmlich daran, dass ich die einzelnen Entwicklungsschritte weitgehend unabhängig voneinander umsetzen konnte, sodass davon ältere Code-Teile nur bedingt berührt waren.
Mit wachsender Größe der Codebasis wird es aber immer heikler, weitere Änderungen vorzunehmen. Eine gute Testabdeckung kann mir eine gewisse Sicherheit geben, dass ich durch Refactorings keine neuen Fehler einführe, die sich auf bereits funktionierende Teile der Anwendung auswirken. Und natürlich kann ich durch Tests auch abprüfen, ob sich neue Funktionalität so verhält, wie ich das beabsichtige.
Report erstellen
Aber wie schlimm ist es um die Testabdeckung nun eigentlich wirklich bestellt?
Um das zu ermitteln, installiere ich mir das Tool coverage:
pip install coverage
Zunächst führe ich die bestehenden Tests über das Coverage-Tool aus:
pyhton -m coverage run -m unittest
Dadurch wird eine Datei .coverage erstellt, aus der sich ein lesbarer Bericht anfertigen lässt:
python -m coverage report
Bei mir führt das allerdings nur zu einer Fehlermeldung:
No source for code: 'F:\Programmieren\cameractrl\config-3.py'
Was coverage mit config-3.py will, ist mir nicht klar, da ich so eine Datei nicht in meinem Projekt habe.
Zunächst kann ich den Fehler aber ignorieren:
python -m coverage report -i
Das spuckt mir die Informationen in der Commandozeile aus. Schöner geht das in Html:
python -m coverage html -i
Das Ergebnis landet im Ordner htmlcov und kann (wer hätte es gedacht) über die index.html im Browser angesehen werden.

Zunächst bin ich überrascht, dass ich immerhin 65% Code-Abdeckung erreiche. Bei genauerer Betrachtung sieht das dann aber gar nicht mehr so toll aus, denn:
- Die Tests selbst sind enthalten.
- Selbst in einer ungetesteten Datei wie
timelapse.pyerreiche ich immerhin 16% Abdeckung, da triviale Teile wie Includes oder Klasseninitialisierung (dadurch dass sie indirekt in einen Test eingebunden sind) im Test ausgeführt werden und entsprechend abgedeckt sind. - Etliche Projektdateien werden in den Tests noch gar nicht inkludiert, tauchen also in der Testabdeckung gar nicht auf.
Mir gefällt am Html-Report, dass ich in die einzelnen Dateien schauen kann und darin übersichtlich markiert sehen kann, welche Zeilen abgedeckt sind und welche nicht. Hier ein Aussschnitt:

Also erstmal die Tests ausschließen:
python -m coverage html --omit="*/tests/*" -i
Schon ist die Gesamtabdeckung auf 52% abgesunken. Wollte ich die Abdeckung nicht erhöhen? Richtig bergab wird es wohl erst gehen, wenn alle Dateien berücksichtigt werden.
Als flexiblere und permanentere Lösung entscheide ich mich, die Tests über eine .coveragerc-Datei auszuschließen. Dort lassen noch viele weitere Einstellungen vornehmen. Und so sieht das bei mir aus:
[run]
source = .
omit = */tests/*
concurrency =
thread
multiprocessing
parallel = True
[report]
ignore_errors = True
skip_empty = True
omit =
./config-3.py
./config.py
[html]
directory = tests/coverage/html_report/
Unter [run] kann ich also nun die Tests mittels omit ausschließen.
Die Angabe source = . sorgt dafür, dass das aktuelle Verzeichnis für die Ermittlung der Coverage berücksichtigt wird. So werden auch Dateien gelistet, die gar nicht in den Tests referenziert sind.
Die Abdeckung ist dadurch auf den für mich glaubwürdigen Wert von 31% abgesunken.
concurrency = thread, multiprocessing (und das dazugehörige parallel) gebe ich an, weil beides in meinem Code vorkommt. Es kann wohl sonst zu stark verfälschten Ergebnissen kommen. In meinem Fall habe ich keinen Unterschied gesehen, vermutlich weil es nur am Rande vorkommt (und gar nicht in den Tests).
Ich habe lange gebraucht, um festzustellen, dass bei Angabe dieser Option noch ein zusätzlicher Schritt vor dem Erstellen des Berichts nötig ist, um die Dateien der einzelnen Threads zusammenzuführen:
python -m coverage combine
Da ich das nicht gemacht hatte, wurde immer eine alte .coverage-Datei herangezogen.
Dass (vor dem combine) aktuell immer nur eine spezifische Prozess-Coverage-Datei entsteht, deutet für mich darauf hin, dass es aktuell nicht nötig wäre, concurrency zu berücksichtigen.
Unter [report] sorge ich mit ignore_errors dafür, dass Fehler immer ignoriert werden (also quasi das -i der Kommandozeile). skip_empty schließt leere Dateien aus dem Bericht aus.
Um die seltsamen Warnungen beim Erstellen des Berichts loszuwerden, schließe ich die fraglichen (nicht existenten) Dateien aus.
Unter [html] gebe ich noch das Ausgabeverzeichnis für den Html-Report an.
Ich habe in coverage keine Möglichkeit entdeckt, sofort nach der Testausführung einen Report zu erstellen, aber über eine Kommandozeilen-Pipeline kann ich genau das erreichen:
python -m coverage run -m unittest | python -m coverage html
bzw. (um concurrency zu berücksichtigen)
python -m coverage run -m unittest | python -m coverage combine | python -m coverage html
Nach all der schönen Spielerei habe ich natürlich noch immer keinen einzigen Test geschrieben. Aber die Übersicht finde ich schon sehr hilfreich (und hoffentlich motivierend, wenn die Abdeckung sichtbar nach oben klettert):

Report automatisiert veröffentlichen
Und natürlich konnte ich die Finger nicht davon lassen und musste es wieder übertreiben. Mein neues Ziel: Den Coverage Report automatisch über die Bitbucket Pipeline erstellen und einsehbar machen.
Zuerst habe ich in der bestehenden Pipeline (in bitbucket-pipelines.yml) im script-Teil meines Test-Schritts den letzten Befehl - python -m unittest discover tests/ durch die drei Befehle zum Erstellen des Reports ersetzt:
- python -m coverage run -m unittest
- python -m coverage combine
- python -m coverage html
Ich musste noch die Python-Library coverage zu tests/requirements.txt hinzufügen, damit es für die Pipeline automatisch mit installiert wird (siehe bitbucket-pipelines.yml).
Außerdem habe ich dafür gesorgt, dass über den Test-Schritt hinweg die Report-Daten als Artefakt erhalten bleiben (per Default für 14 Tage):
artifacts:
- tests/coverage/html_report/*
Das konnte ich dann auch schon in Bitbucket über die Pipeline als Archiv herunterladen.
Als nächstes habe ich einen weiteren Schritt zum Übertragen der Ergebnisse zu den Projekt-Downloads eingerichtet.
- step:
name: Upload Test Results
script:
- pipe: atlassian/bitbucket-upload-file:0.7.1
variables:
BITBUCKET_ACCESS_TOKEN: $BITBUCKET_ACCESS_TOKEN
FILENAME: 'coverage_report.md'
Die Variable $BITBUCKET_ACCESS_TOKEN konnte ich in den Bitbucket ‘Repository Settings’ unter ‘Pipelines -> Repository Variables’ definieren. Dafür habe ich zuvor (ebenfalls in den ‘Repository Settings’) unter ‘Security -> Access Tokens’ ein Token mit Lese- und Schreibzugriff auf das Repository eingerichtet und den Schlüssel dann in der Variable hinterlegt.
Ich habe dabei herausgefunden, dass es ein Limit von 10 Dateien für die Übertragung zu den Downloads gibt und daher statt des Html-Reports einen Text-Report im Markdown-Format generiert:
- python -m coverage report --format=markdown > coverage_report.md
So richtig überzeugt hat mich das aber noch nicht. Ich hatte dann eine neue Idee:
- Html-Report erstellen
- Report in Zip-Archiv packen und zu den Downloads übertragen
- Ein Skript auf meiner Webseite triggern, das die Datei herunterlädt, auspackt und in einem Unterverzeichnis der Webseite zu Verfügung stellt
Html-Report zippen
Der entsprechende Ausschnitt aus bitbucket-pipelines.yml:
- python -m coverage html
- zip -r -j coverage_report.zip tests/coverage/html_report
artifacts:
- coverage_report.zip
Der zip-Befehl hat die Parameter -r für rekursiv (wäre vermutlich gar nicht nötig, denke ich mir gerade) und -j was dafür sorgt, dass die Dateien flach ins Archiv kopiert werden (also ohne Verzeichnisstrukturen). Bei einem vorigen Versuch war mir nämlich aufgefallen, dass im Archiv der Pfad tests/coverage/html_report erhalten geblieben war, was ich vermeiden wollte.
Nicht vergessen: Zip muss im Docker-Container der Pipeline installiert sein. Zu all den anderen Projekt-Abhängigkeiten kommt das also nun noch dazu:
- apt-get update && apt-get install ffmpeg libsm6 libxext6 iputils-ping zip -y
Mir ist bewusst, dass dieser Installationsschritt sowie die ganzen Python-Library-Installationen bei jedem Ausführen der Pipeline wieder neu durchgeführt werden. Ich finde es beeindruckend, dass die gesamte Pipeline (einschließlich der nicht gerade schnellen Tests) in weniger als 2 Minuten durchläuft. Dennoch wäre es sinnvoll, einmal einen Docker-Container mit all den benötigten Abhängigkeiten zu erstellen und dann in der Pipeline zu verwenden.
Website-Script triggern
Mein Pipeline-Schritt Upload Test Results überträgt nun das Zip-Archiv und sendet abschließend noch über cUrl einen Request an meine Webseite:
- step:
name: Upload Test Results
script:
- pipe: atlassian/bitbucket-upload-file:0.7.1
variables:
BITBUCKET_ACCESS_TOKEN: $BITBUCKET_ACCESS_TOKEN
FILENAME: 'coverage_report.zip'
- curl $COVERAGE_REPORT_SYNC_URL
Die Url habe ich wieder hinter einer Variable versteckt, weil ich nicht unbedingt öffentlich einsehbar haben möchte wo das Skript liegt und wie man es bedient (mir ist auch klar, dass sich das mit etwas Mühe bestimmt irgendwie rauskriegen lässt).
Interessant dürfte sein, dass es ein PHP-Skript ist, welches als Url-Parameter den Projekt-Namen erwartet, also etwa so:
https://josawode.de/irgendein/pfad/irgendein_name.php?projectName=cameractrl
Als weitere Optimierung habe ich den Upload inzwischen als after-script des Test-Pipeline-Schritts definiert. So entfällt der zweite Schritt, es muss also kein neuer Container gestartet werden und das Erstellen eines Artefakts ist nicht mehr nötig. Der eigentliche Grund liegt aber darin, dass der Coverage Report nun auch aktualisiert wird wenn Tests fehlschlagen.
Python-Skript über PHP ausführen
Ich bin alles andere als ein PHP-Experte, daher habe ich das Skript auch nur genutzt, um ein Python-Skript zu triggern, welches die eigentliche Arbeit macht. Das PHP-Skript sieht ungefähr so aus:
<?php
// Url-Parameter auslesen
$projectName = htmlspecialchars($_GET["projectName"]);
// Python-Skript Befehl
$command = "/usr/bin/python3.11 /absoluter/skript/pfad/update_coverage.py
--project_name {$projectName}";
// Befehl ausführen
$output = null;
$retval = null;
exec($command, $output, $retval);
// Ergebnis ausgeben
echo $retval;
?>
Ich habe in meinem Python-Skript das Shebang angegeben, damit es funktioniert ohne python oder ähnliches davor schreiben zu müssen. Das hat auf meinem Windows-Rechner in der Git-Bash problemlos funktioniert, aber auf dem Server wollte es nicht, obwohl es sogar in der Dokumentation steht (und es lag nicht an den Dateirechten).
Daher habe ich nun direkt den Pfad zu einer spezifischen Python-Installation angegeben.
Auch habe ich zuerst erfolglos andere Varianten ausprobiert, den Befehl auszuführen, z.B. hatte ich mit shell_exec keinen Erfolg, aber das mag auch an meiner Unkenntnis liegen.
Das Ergebnis ist 1 für Erfolg und 2 für Fehlschlag, was mich etwas wundert. Ich hätte im Erfolgsfall eigentlich 0 erwartet. Als Rückmeldung beim manuellen Ausführen im Browser bin ich damit zufrieden. Es wäre bestimmt möglich, die detaillierten Ausgaben des Python-Skripts im Browser auszugeben, aber das möchte ich gar nicht, denn dann würden wieder unnötig Detail-Informationen über die Benutzung nach außen gegeben (z.B. welche Projekte abgefragt werden können, aber dazu gleich mehr).
Übertragung und Veröffentlichung des Coverage-Reports
Das Python-Skript liegt natürlich nicht im öffentlichen Bereich der Webseite.
Im Skript habe ich ein Dictionary projects hinterlegt, das zu jedem Projekt (aktuell nur CameraCtrl die benötigten Infos enthält):
projects = {
'cameractrl': {
'download_url':
'https://bitbucket.org/ausguss/cameractrl/downloads/coverage_report.zip',
'target':
Path(__file__).parent /
'öffentlicher/pfad/zur/webseite/coverage_reports/cameractrl',
'is_archive': True
}
}
Ich habe zum Parsen des Kommandozeilenarguments wohl etwas Overkill betrieben, da ich gerne mal argparse verwenden wollte. Da argparse mir fast die ganze Arbeit abnimmt, hat es sich aber vielleicht sogar für den einen Parameter schon gelohnt.
Parser anlegen:
from argparse import ArgumentParser
if __name__ == '__main__':
parser = ArgumentParser(
prog='Coverage Report Updater',
description='Retrieves the coverage report for a project and publishes it.',
epilog='')
Im Konstruktor des Parsers kann ich gleich ein paar Informationen hinterlegen, die dann beim Anzeigen der Hilfe (Aufruf des Skripts mit Parameter -h oder --help) mit ausgegeben werden.
Argument hinzufügen:
parser.add_argument("--project_name", action='store', type=str, required=True,
choices=projects.keys(),
help="Pass the name of the project for which to update report.")
action='store' ist der Default und besagt einfach, dass nach dem Parameter ein Wert übergeben wird, der von argparse gespeichert wird.
Ich kann den Typ (String) angeben und stelle über required ein, dass es ein zwingend erforderlicher Parameter ist. Über choices kann ich angeben, welche Werte zulässig sind (in dem Fall die keys meines projects-Dictionary, aktuell also nur cameractrl).
Nun noch die Argumente parsen und verwenden:
args = parser.parse_args()
res = update_coverage_report(args.project_name)
sys.exit(1 if res else 0)
Das ist schon alles. argparse beendet bei Falscheingaben (z.B. unzulässiger oder fehlender Projektname) direkt die Anwendung mit einer hilfreichen Ausgabe. Das sieht dann z.B. so aus:
usage: Coverage Report Updater [-h] --project_name {cameractrl}
Coverage Report Updater: error: the following arguments are required: --project_
name
Und bei Aufruf der Hilfe:
usage: Coverage Report Updater [-h] --project_name {cameractrl}
Retrieves the coverage report for a project and publishes it.
options:
-h, --help show this help message and exit
--project_name {cameractrl}
Pass the name of the project for which to update
report.
Tada, fertig, ich bin begeistert!
Wobei ich die Funktion update_coverage_report vielleicht nicht unterschlagen sollte.
Zunächst lade ich das Archiv mit dem Report herunter:
from urllib.request import urlretrieve
urlretrieve(project['download_url'], temp_file)
Dann entpacke ich es in ein temporäres Verzeichnis:
from tempfile import TemporaryDirectory
from zipfile import ZipFile
with TemporaryDirectory() as temp_dir:
with ZipFile(temp_file, 'r') as zip_ref:
zip_ref.extractall(temp_dir)
Ich nutze shutil.move, um innerhalb des Kontext des temporären Verzeichnis, die entpackten Dateien an ihr Ziel zu verschieben. Sobald der Kontext (das with) verlassen wird, sorgt tempfile dafür, dass das Verzeichnis entfernt wird.
tempfile bietet natürlich auch Funktionalität für temporäre Dateien, aber ich habe das lieber selber gehandhabt, weil es für mich so aussieht, als ob die temporären Dateien über tempfile immer direkt geöffnet sind und das wollte ich hier nicht.
Das war jetzt aber wirklich alles. Und so sieht die Update-Funktion im Ganzen aus:
import logging
from pathlib import Path
import shutil
import sys
from tempfile import TemporaryDirectory
from urllib.error import HTTPError
from urllib.request import urlretrieve
from zipfile import ZipFile
def update_coverage_report(project_name: str) -> bool:
project = projects[project_name]
temp_file = Path('coverage_report_temp.file')
temp_file.unlink(missing_ok=True)
try:
urlretrieve(project['download_url'], temp_file)
if project['is_archive']:
with TemporaryDirectory() as temp_dir:
with ZipFile(temp_file, 'r') as zip_ref:
zip_ref.extractall(temp_dir)
# Prepare target
if project['target'].exists():
shutil.rmtree(project['target'])
project['target'].mkdir()
# Move files
for file in Path(temp_dir).iterdir():
shutil.move(file, project['target'])
else:
shutil.move(temp_file, project['target'])
logging.info(f'Updated coverage report for {project_name} successfully.')
return True
except (HTTPError, OSError) as e:
logging.error(e)
logging.error(f'Failed to update coverage report for {project_name}.')
return False
finally:
# Cleanup
temp_file.unlink(missing_ok=True)
Wie der Report aussieht weißt du ja schon. Und die Testabdeckung ist irgendwie auch nicht von selbst größer geworden. Hier kannst du dich im Detail durch den Report klicken: CameraCtrl Test Coverage Report
Tests zu Bild- und Video-Funktionalität mit Numpy
Ich habe beim Timelapse Editor endlich meine ersten Schritte in Numpy gewagt und bin dabei zwar noch etwas wackelig auf den Beinen, aber sehr begeistert.
Interessiert hat mich in diesem Fall insbesondere die Array-Funktionalität, da Bilder im Grunde nichts anderes als Arrays sind und ich so Bilder recht einfach generieren oder untersuchen konnte.
Numpy habe ich weiter oben beim Thema Graph View schon kurz erwähnt und dort auch verwendet genauso wie an manchen anderen Stellen, da einige der verwendeten Libraries damit arbeiten. Aber beim Schreiben von Tests zu Bild- und Video-Funktionalität habe ich tatsächlich zum ersten Mal selbst etwas damit zustande gebracht.
Hier ein paar beispielhafte Auszüge, wie ich es in den Tests verwenden konnte:
Bilder zum Testen erstellen:
# Schwarzes Bild
arr = np.zeros((200, 100, 3), dtype=np.uint8)
# Weißes Bild (mit Alpha-Kanal)
arr = np.full((200, 100, 4), 255, dtype=np.uint8)
# Gestreiftes Bild
red = np.array([255, 0, 0], dtype=np.uint8)
turquoise = np.array([0, 123, 123], dtype=np.uint8)
arr = np.zeros((200, 100, 3), dtype=np.uint8)
arr[::] = red
arr[::2] = turquoise
# Bild in PIL.Image konvertieren und abspeichern
im = Image.fromarray(arr)
im.save(img_path)
# Bild mit PIL laden und in Array umwandeln
with Image.open(file_path) as image:
array = np.array(image)
Durchschnittliche Farbwerte berechnen:
Das waren ohne Numpy acht Codezeilen.
def average_color(array: np.array) -> tuple[float, float, float]:
average = np.mean(array, axis=(0, 1))
return average[0], average[1], average[2]
Bilder überprüfen:
# Oben 50 Pixel schwarzer Rand
self.assertTrue(np.all(image[0:50, :] == 0))
# Unten 50 Pixel schwarzer Rand
self.assertTrue(np.all(image[-50::, :] == 0))
# Und der Rest ist weiß
self.assertTrue(np.all(image[50:150:, :] == 255))
# Oben 50 Pixel annähernd schwarzer Rand
self.assertTrue(np.all(image[:50, :] < 10))
# Das Bild weicht im Farbdurchschnitt nur wenig von einer vorgegebenen Farbe ab
average = average_color_of_numpy_array(image)
average += (255,) # Alpha-Channel hinzufügen
diff = average - color
self.assertTrue(np.all(diff < 10))
Falls du auch schon mal über mehrfach verschachtelte for-Schleifen durch Arrays gewandert bist, um irgendwelche Informationen zusammenzusuchen oder Berechnungen zu machen, kannst du meine Begeisterung sicher nachvollziehen.
Client UI aufpolieren
Das was ich bisher Client UI genannt habe war ja nichts anderes als eine Textwand und ein paar Knöpfe. Das sah neben dem aufwändigen Timelapse Editor nun doch etwas arg kümmerlich aus, daher habe ich mich entschieden die UI ähnlich der Schwarm-Übersicht im Browser neu zu gestalten. Dafür habe ich auch die Server-Funktionalität leicht angepasst und erweitert sowie ein paar Bugs gefixt.
So werden die einzelnen Kameras nun dargestellt:

Über “All Devices” lassen sich alle Kameras auf einmal starten/pausieren, synchronisieren und so weiter. Dadurch sind ein paar Buttons aus der alten Button-Leiste überflüssig geworden. (Übrigens sehe ich ein, dass ich das Icon für den Button zum Aktualisieren der Liste austauschen sollte. Ich habe nun schon mehrfach darauf geklickt, als ich eigentlich die Bilddateien synchronisieren wollte.)
Der etwas spezielle AllDevicesListEntry erbt vom gewöhnlichen DeviceListEntry.
Das Layout mit Bild, Labels und allen Buttons ist dabei (fast) komplett im DeviceListEntry definiert. Wenn kein Preview-Bild vorhanden ist (was für “All Devices” immer zutrifft), wird es versteckt (sonst wäre der Hintergrund weiß statt schwarz).
Die Buttons werden aus dem Layout entfernt, wenn die entsprechende Funktion nicht im Konstruktor übergeben wurde, z.B.:
if self._refresh_func is None:
self.ids.btn_layout.remove_widget(self.ids.refresh_btn)
self.ids.pop('refresh_btn')
Die Liste (im MainScreen) wird bei Anwendungsstart aufgebaut und wenn der “Refresh”-Button geklickt wurde. Beim Anwendungsstart erwies es sich jedoch als lästig, mit dem Aufbau der UI zu warten bis die Liste aufgebaut ist, denn sie wird ja per Request vom CameraCtrl Schwarm abgefragt.
Im Normalfall geht das schnell, aber wenn ich die Geräte ausgeschaltet habe, möchte ich definitiv nicht auf den Timeout warten bis ich den Timelapse Editor benutzen kann.
Der Trick liegt (mal wieder) im Entkoppeln des Requests durch den APScheduler:
def _init_devices(self):
self.ids.device_list.clear_widgets()
all_entry = AllDevicesListEntry(
sync_folder=self.client.config.shots_dir,
open_in_browser_func=self.open_server_in_browser,
play_state_func=self.client.change_swarm_play_state,
sync_func=self.sync,
shutdown_func=self.shutdown,
refresh_func=self._init_devices,
status_change_callback=self._device_status_change_callback)
self.ids.device_list.add_widget(all_entry)
@mainthread
def _build_device_list(devices: dict):
for mac_address, device in devices.items():
device_preview = DeviceListEntry(mac_address, device,
sync_folder=self.client.get_sync_folder(mac_address),
open_in_browser_func=self.open_server_in_browser,
status_func=self.client.update_status,
sync_func=self.sync,
shutdown_func=self.shutdown,
status_change_callback=self._device_status_change_callback,
update_preview_func=self.update_preview)
self.ids.device_list.add_widget(device_preview)
def _request_devices():
devices = self.client.get_swarm_devices()
_build_device_list(devices)
# Avoid blocking the ui while waiting for the device request to finish
self._scheduler.add_job(_request_devices, 'date', run_date=datetime.now())
Wichtig ist dabei, dass das eigentliche Anlegen der DeviceListEntrys dann wieder im Main-Thread passiert (Dank @mainthread), sonst provoziert man einen Absturz.
Hier kann man auch sehen, wie die ganze Funktionalität in die Einträge reingestopft wird. Das hätte man sicher auch noch etwas schöner kapseln können in einem eigenen kleinen Verwaltungsobjekt oder so, aber ich bin zufrieden. Den übergebenen Callbacks wird beim Aufruf dann die Mac-Adresse des jeweiligen Geräts übergeben.
Abgesehen vom Öffnen des lokalen Synchronisations-Ordners löst jede Aktion (mindestens) einen Request an die Schwarm-API aus.
Ausfürbare Dateien bauen
Bisher habe ich meinen CameraCtrl-Client immer über die Python-Dateien gestartet und dabei meinen aktuellen Entwicklungsstand verwendet. Nun wollte ich ausführbare Dateien erzeugen, die unabhängig vom aktuellen Zustand meiner Entwicklungsumbegung (einschließlich verwendeter Libraries) lauffähig sein sollten.
Ich habe die UI minimal angepasst, sodass sie nun optional als Standalone Timelapse Editor gestartet werden kann. So kann ich zwei Installer bauen, einmal für den vollen CameraCtrl Client, der nur im Zusammenhang mit einem Raspberry Pi Kamera Server sinnvoll ist, und einmal für den Timelapse Editor, der auch unabhängig davon für das Erstellen von Timelapse Videos aus Bilddateien genutzt werden kann.
Neben dem bisherigen (sehr überschaubaren) Start-Skript run_client_ui.py gibt es nun ein zweites namens run_client_ui_editor_only.py, das fast identisch ist, nur dass es der Anwendung über den Konstruktor mitteilt doch bitte nur den Timelapse Editor zu zeigen.
Auch wenn der Code weitgehend plattformunabhängig gestaltet ist, habe ich mich entschieden erstmal nur Windows als Zielplattform zu berücksichtigen. Auf Linux und macOS dürften der CameraCtrl Client und Timelapse Editor nach kleineren Anpassungen schon lauffähig sein, aber ich möchte mir den Aufwand das einzurichten und gründlich zu testen aktuell ersparen. Für mobile Plattformen wäre der Anpassungsaufwand sicher noch etwas größer, um Touch-Bedienung und andere Gegebenheiten (z.B. bezüglich Fenster-Management) zu berücksichtigen (falls überhaupt alle Abhängigkeiten wie z.B. FFmpeg für mobile Plattformen verfügbar sind).
PyInstaller über Python-Script ausführen
Der PyInstaller durchwühlt ein Projekt nach allem was darin vorkommt einschließlich der Abhängigkeiten zu externen Libraries und packt es zusammen zu einem in sich geschlossenen lauffähigen System. Um das zu erreichen muss man allerdings an ein paar Stellen noch nachhelfen.
Meistens bedient man den PyInstaller über Kommandozeilenaufrufe und Spezifikationsdateien. Ich wollte ihn aber lieber über ein Python-Skript ausführen.
Das geht ganz ähnlich, nur dass man die Optionen nicht in der Kommandozeile hintereinanderschreibt, sondern in eine Liste steckt:
import PyInstaller.__main__
options = [
str(script_path),
# '--clean', # kann man verwenden, um immer alles gründlich neu zu bauen
'--name', 'CameraCtrlClient',
'--icon', str(icon_path),
'--distpath', str(target_folder_path),
'--onefile',
'--windowed',
'--collect-submodules', 'client',
'--collect-submodules', 'utils',
]
PyInstaller.__main__.run(options)
Nun galt es aber noch etwas zu tricksen, damit das Ergebnis auch wirklich lauffähig wurde. Ich habe also noch eine ganze Reihe weiterer options ergänzt.
Bilder und .kv-Dateien übernehmen:
data_paths = [source_dir / 'client' / 'kv', source_dir / 'client' / 'static']
for path in data_paths:
options.append('--add-data')
source = str(path)
target = path if path.is_dir() else path.parent
target = str(target.relative_to(source_dir))
options.append(f'{source}:./{target}')
Der Plyer-Filechooser hat die plattformspezifische Implementierung hinter Fassaden versteckt und damit leider auch den PyInstaller getäuscht. Also musste ich ihm beibringen wo das gute Zeug versteckt ist (zumindest für Windows hat es funktioniert):
platform_str = 'win'
if sys.platform.startswith('linux'):
platform_str = 'linux'
elif sys.platform.startswith('macos'):
platform_str = 'macosx'
elif sys.platform.startswith('android'):
platform_str = 'android'
elif sys.platform.startswith('ios'):
platform_str = 'ios'
options.append('--hidden-import')
options.append(f'plyer.platforms.{platform_str}.filechooser')
Kivy-DLLs dazupacken:
for p in (sdl2.dep_bins + glew.dep_bins + gstreamer.dep_bins + angle.dep_bins):
options.append('--add-data')
options.append(str(Path(p).as_posix()) + ':.')
Kivy spricht nur von sdl2 und glew, daher möchte ich irgendwann noch prüfen, ob auf die anderen Abhängigkeiten verzichtet werden kann.
FFmpeg-Binaries mit einpacken:
ffmpeg_data_path = Path('C:\\ffmpeg\\bin\\')
options.append('--add-data')
options.append(str(ffmpeg_data_path.as_posix()) + ':.')
Wie man sieht, habe ich beim FFmpeg-Pfad geschummelt. Das funktioniert natürlich nur auf meinem Rechner (bzw. auf Windows-Rechnern bei denen FFmpeg in diesem Pfad installiert wurde). Besser wäre es hier über die Pfad-Variable nach den FFmpeg-Binärdateien zu suchen (oder sich etwas anderes Schlaues einfallen zu lassen).
Mögliche Optimierungen
Die ausführbaren Dateien sind mit 380MB recht groß. Das ist nicht weiter tragisch, aber ich glaube, dass ich hier noch einige unnötige Includes (insbesondere von Binärdateien) loswerden könnte.
Bei jedem Start wird die ausführbare Datei in ein temporäres Verzeichnis (irgendwo im System) ausgepackt. Das ginge sicher schneller, wenn sie in der Größe reduziert wäre.
Es ist aber auch eine Überlegung, auf die Option --onefile zu verzichten, die alle Abhängigkeiten mit in der ausführbaren Datei bündelt. Stattdessen könnte dann das Ergebnis des PyInstaller-Build in ein Archiv gesteckt werden, das man dann (sozusagen als Installation) einmalig entpackt.
Audio zu Video hinzufügen mit FFmpeg
Es ist mir nach vielen Stunden verzweifelter Fehlersuche nicht gelungen, das Projekt so zu bauen, dass die Audio-Generierung mit MoviePy über die ausführbare Datei noch funktioniert. Zudem hatte mich schon zu Beginn gestört, dass die MoviePy-Library etwas ungepflegt daher kommt und veraltete Projektabhängigkeiten mit sich bringt. Daher hatte ich nun genug Gründe gesammelt, diese Abhängigkeit loszuwerden (ich verwende es allerdings weiterhin für die Tests).
Ich habe mich entschieden, stattdessen auf ffmpeg-python zu setzen, einen FFmpeg-Wrapper für Python. FFmpeg ist sehr mächtig allerdings in der Benutzung auch deutlich anspruchsvoller, als das sehr zugängliche MoviePy.
Frankfurt-Fans schreiben FFmpeg übrigens mit großem ‘M’.
Falls ich die Anwendung über eine ausführbare Datei gestartet habe, möchte ich die darin enthaltenen FFmpeg-Executables verwenden. So ist sichergestellt, dass sie immer vorhanden sind, auch gefunden werden und kompatibel mit meinem Code sind. Das bringe ich ffmpeg-python bei, indem ich bei den entsprechenden Aufrufen falls nötig den Pfad anpasse, z.B.:
run_cmd = 'ffmpeg'
if hasattr(sys, '_MEIPASS'):
# noinspection PyProtectedMember
run_cmd = str((Path(sys._MEIPASS) / 'ffmpeg').resolve())
ffmpeg.run(stream, cmd=run_cmd, overwrite_output=True)
_MEIPASS ist in der ausführbaren Datei gesetzt und verweist auf den lokalen Pfad, also das temporäre Verzeichnis in das beim Start alles entpackt wurde.
Für ffprobe gehe ich analog vor.
ffprobe erlaubt, etliche Informationen aus einer Audio- oder Video-Datei auszulesen. Ich ermittle darüber die Abspieldauer in Sekunden (hier für das Video):
probe = ffmpeg.probe(input_video_file_str, cmd=probe_cmd)
video_stream = next((stream for stream in probe['streams']
if stream['codec_type'] == 'video'), None)
video_duration = float(video_stream['duration'])
Nun gilt es für jede Audio-Datei die Startposition zu setzen:
audio_input = ffmpeg.input(input_audio_file_str)
if start_sec == 0:
audio = audio_input.audio
else:
delay_ms = round(start_sec * 1000)
audio = audio_input.audio.filter('adelay', f'{delay_ms}:all=1')
audio_list.append(audio)
Falls die Abspiellänge kleiner ist als die gewünschte Zeit, füge ich das Audio entsprechend versetzt mehrfach ein:
current_audio_end = start_sec + audio_duration
while current_audio_end < end_sec:
delay_ms = round(current_audio_end * 1000)
audio_clone = audio_input.audio.filter('adelay', f'{delay_ms}:all=1')
audio_list.append(audio_clone)
current_audio_end += audio_duration
Und falls ich am Ende über das Ziel hinausschieße muss noch entsprechend gekürzt werden (einschließlich Fade-Out):
if current_audio_end > video_duration:
audio_list[-1] = audio_list[-1].filter('atrim', end=video_duration)
audio_list[-1] = audio_list[-1].filter('afade', t='out', st=video_duration - 2, duration=2)
Nun werden die Audio-Streams zusammengemischt und das Ergebnis normalisiert:
merged_audio = ffmpeg.filter(audio_list, 'amix', inputs=len(audio_list),
duration='longest',
dropout_transition=video_duration)
merged_audio = ffmpeg.filter(merged_audio, 'dynaudnorm')
Wenn die dropout_transition kleiner als die Gesamtabspiellänge ist, kommt es zu seltsamen Effekten bei der Laustärke, daher habe ich sie entsprechend gesetzt.
Den fertigen Audio-Stream kann ich nun mit dem Video verknüpfen:
input_video = ffmpeg.input(input_video_file_str)
stream = ffmpeg.concat(
input_video,
merged_audio,
v=1, a=1
)
So weit ich die Sache verstehe, diente all das nur der Vorbereitung, also dem Zusammenbau des FFmpeg-Befehls. Diesem Befehl wird nun noch der Pfad für die zu schreibende Video-Datei angehängt und dann wird er über ffmpeg.run ausgeführt:
try:
stream = ffmpeg.output(stream, str(video_out_path.resolve()))
ffmpeg.run(stream, cmd=run_cmd, overwrite_output=True)
except ffmpeg.Error as e:
logging.info('Failed to write audio to video')
logging.info(e)
Fertig
Jedes Mal wenn ich mich mit CameraCtrl oder dem Timelapse Editor beschäftige fallen mir noch neue Sachen ein/auf, die ich erweitern oder verbessern könnte.
Ich denke aber, dass das Projekt jetzt einen Zustand erreicht hat, in dem ich es vorerst belassen kann und will, um mich anderen Dingen zuwenden zu können.
Wobei ich vermutlich noch den ein oder anderen Bug fixen werde, der mir bei der Benutzung auffällt.
In jedem Fall wäre ich überrascht, wenn ich daran noch etwas fände über dass sich lohnen würde zu schreiben (außer ich gehe das Thema Video an, aber das ist für mich aktuell nicht von Interesse).
Ich habe sowohl beim Coden als auch beim darüber Schreiben eine Menge über Python, Kivy, Raspberry Pi und Linux gelernt – mindestens. Und echt Spaß daran gefunden.
Ich würde mich sehr freuen, wenn die Dokumentation und der Code – oder sogar der Timelapse Editor – nicht nur mir hilft, sondern vielleicht auch mal andere darüber stolpern, die etwas damit anfangen können.
Falls du dazu gehörst, wende dich bei Fragen oder Problemen gerne an mich.